MEAN’s great, but then you grow up.
The MEAN stack (MongoDB, Express.js, Angular.js, Node.js) is now being heralded as the new LAMP (Linux, Apache, MySQL, PHP), the preferred technology stack for startups.
MEAN is certainly a great technology choice for organizations (particularly startups) seeking to rapidly prototype a capability. However, like all technology choices, the MEAN stack comes with a number tradeoffs. Once you’ve hit some level of success or maturity with MEAN, you should re-evaluate the utility of the individual MEAN technologies as they pertain to your product.
This post is a set of revelations you will probably encounter after the first year of using MEAN, particularly when your product has seen some adoption.
MongoDB
MongoDB is a great database. I say this upfront because I’m going to criticize the way it is often abused by developers who don’t understand its model and use cases. I don’t want you to interpret this as me advocating you avoiding MongoDB.
Like all databases, MongoDB has a sweet-spot. Its great for the storage of schema-less documents where access to records is at the “document-level” (e.g. not pieces of documents). MongoDB is very fast, but it achieves its performance by trading off consistency (in clustered setups). Thus, MongoDB is great when you need speed, flexibility in your model and can accept minor and relatively infrequent data loss.
However, Mongo may not be the optimal choice for your data storage and access needs.
There are a number of factors you need to consider when selecting a database. One mistake engineers make when they design an application is to prematurely optimize the system for scale and performance before they have any real metrics. While MongoDB is touted as a “web scale” database, it comes at the cost of features provided by more traditional forms of storage like relational databases (MySQL, PostgresSQL, etc).
A satirical comparison of MongoDB and MySQL.
MongoDB Consistency.
MongoDB claims to be strongly consistent, but a lot of evidence recently has shown this not to be the case in certain scenarios (when network partitioning occurs, which can happen under heavy load) [1] [2]. This means that you can potentially lose records that MongoDB has acknowledged as “successfully written”. Kyle Kingsbury writes an excellent article on his well known blog “Aphyr” about this scenario: http://aphyr.com/posts/284-call-me-maybe-mongodb.
In terms of your application, if you have a need to have transactional guarantees (meaning if you can’t make a durable write, you need the transaction to fail), you should avoid MongoDB. Example scenarios where strong consistency and durability are essential include “making a deposit into a bank account” or “creating a record of birth”. To put it another way, these are scenarios where you would get punched in the face by your customer if you indicated an operation succeeded and it didn’t.
Don’t drop MongoDB just yet.
The first step to solving a problem is know you have a problem. If your system can’t tolerate data loss, but the domain isn’t necessarily “bank account worthy” of transactional guarantees (e.g. a comment on a post), you can take external steps to guarantee data protection. For instance, you can log records externally (file system, log aggregator, etc.) and have a process that verifies the integrity of those records. This is especially true if your data set is immutable (meaning records do not get updated once they are created).
MongoDB is always being patched or updated. It’s possible that some of these concerns will get fixed in the next couple of months and this point will be moot.
Realistically, the first problem you will likely encounter with MongoDB will be model related, not a consistency issue.
Access and Storage Patterns.
MongoDB is a document database where the document format is JSON (errr…BSON). MongoDB will allow you to flexibly query records using properties on JSON documents, however, it’s not really designed to do things like Joins (where you create a new record from a set of two or more records). The theory behind a document database is that you keep all pertinent pieces of data together in one data structure. This makes retrieval of a record and all other pertinent information really fast (since no joins are involved). The scope of how much data is stored in that data structure is based on how you intend to access it.
For instance, if I wanted to model a forum, I might consider storing each forum thread as its own JSON document. This means all comments, upvotes, view statistics, etc. would be stored in the same JSON object. Storing all of the information in a JSON object means the schema of the document is going to contain a bunch of nested entities (objects being an indicator), commonly in some form of aggregation (an array or another object). In a normalized database (not Mongo), entities are typically stored in their own containers (table, collection, etc.). This makes working with the individual entities very easy, especially when you want to perform a partial update of a record.
Denormalized data stores like MongoDB come with tradeoffs:
- More difficult to perform partial updates on nested or aggregated entities since the models are buried within each document. This does not mean it’s impossible (MongoDB update operators), but certainly more difficult.
- Difficult to compose new entities from existing aggregates. Meaning, if you want to get all comments for a particular user, but comments are stored in each forum thread, you will have to perform a MapReduce operation over the entire set to retrieve that information.
- Need for record synchronization if you represent the same piece of data in more than one place. For instance, if you keep a user’s name with their comments on a forum post, and the user updates their name in their profile, you will have to iterate through each comment to make the same update.
A rather famous, yet controversial, article was written on this topic: Why You Should Never Use MongoDB. While the title infers that MongoDB was the problem, the real issue was denormalization in a document database didn’t fit Diaspora’s highly-relational model.
So you have to decide what model best fits your dataset. If you don’t need to maintain relationships between records, need partial updates, or need to access/mutate aggregates, I’d say MongoDB is ideal for you.
Maintenance.
MongoDB is not particularly difficult to maintain, but it does have its costs. If you want to employ sharding and replication, you will need to stand up the necessary MongoDB daemons to perform these services, and they will need to be split amongst a couple of servers to be correctly configured. Really, the same is true with any distributed database and your operations team needs to be prepared for the responsibility. In addition, maintaining a Mongo cluster takes some skill and effort, more so than a traditional relational database. Michael Schurter details some of the maintenance effort in Failing with MongoDB.
The key point to take away here is that if your organization is unprepared to operate, monitor, and maintain a MongoDB cluster, you should either find a hosted solution (Mongolab or Compose – formerly MongoHQ) or use another database.
Go polyglot.
No database will ever perfectly meet all of your use cases. So, instead of limiting yourself to one, why not use a couple?
- Full-text search: while MongoDB has a full-text index, it’s not as powerful as other, dedicated solutions: Lucene/Solr, ElasticSearch, Sphinx.
- Relational databases: still the workhorse for a number of huge applications at companies like Facebook and Google. Granted, it takes more code to be productive, and they can much slower when you need to perform Joins, they still offer better overall functionality than most NoSQL solutions.
- Key-Value stores: provide great performance for simple lookups. Some implementations like Redis offer super fast set and incrementing operations.
- Graph databases: if you have a highly connected model, like a social network, a graph database may be your best choice for maintaining those relationships.
Going polyglot isn’t problem free. I guarantee you will be introducing more complexity into your code base and architecture following this route. However, you will likely alleviate some of the performance issues encountered using only one data source.
OK, I’ve hammered on MongoDB long enough. Let’s look at the rest of the MEAN stack.
Express.js
Express.js is probably the most popular and mature server-side MVC framework in the Node.js ecosystem. Countless organizations have built significant applications on the framework without much difficulty.
However, not everyone is content with Express.js. – You may not be as well.
Express, like many frameworks, has to live with its own success. As a piece of software, this usually meaning living with decisions made early in the development of the framework. Some of the problems were detailed by Eran Hammer in his post on why he created Hapi.js:
- Limited extensibility, Eran felt strangled by the middleware (Connect) implementation, particularly when he needed multiple components to coordinate together [3].
- Poor isolation of the server from the business logic which prevented the reuse of services for purposes like batching operations (you don’t want to have to go through the Express middleware chain for an internal request) [3].
- Code instead of configuration, Express emphasized using code (imperative programming) instead using a more declarative model when wiring up middleware and defining routes [3].
In fact, there are now many robust server-side frameworks to choose from in the Node.js ecosystem. To name a few:
If you don’t like Express, it doesn’t take much to move away from it. However, moving to another framework means you will not be able to use a lot of the boilerplate the MEAN project provides you (since much of it is simply a bow-tie around Express). Therefore, this choice is going to involve modifying some configuration around Grunt (the build tool used by the MEAN project) among other things*. Once you are comfortable with the Node.js environment, I think you will find much of this functionality a convenience that you can potentially live with out.
*When I refer to the “MEAN project”, I’m referring to the code written by MEAN.io that provides features like code generation, runtime configuration, and package management. I’m not speaking of the individual technologies in the MEAN stack.
Angular.js
Angular.js is another great framework, one I personally use and advocate for most web projects. However, in certain circumstances, Angular.js may not be the best framework for your needs.
Your heart might belong to another framework.
Angular’s programming model borrows a lot of idioms from the Java world (dependency injection, namespaces, etc.). Angular also promotes the separation of DOM manipulation code into directives, the use of a scope hierarchy with dirty state checking, and some behavior defined directly in templates. Together, this style of programming is likely to turn some people off.
But…that’s ok.
JavaScript has a number of really good Single Page Application frameworks and if Angular doesn’t match your style, I’m sure some other will:
And many, many more…
Angular.js may be too difficult for your team.
A common complaint about Angular is that it is too hard to learn. I don’t find this to be the case, but I came to the framework with years of JavaScript experience. Needless to say, other disagree with me. Probably the most vocal is George Butiri in his post The Reason Angular.js Will Fail. Personally, I think he’s failed to grasp some of the core concepts of Angular, but I guess this notion may reinforce his case.
Even if you really like Angular, and think it was easy to pick up, there is validity to the idea that your team may not feel the same way. So, you may find a need to migrate to another framework if you can’t recruit a competent Angular team.
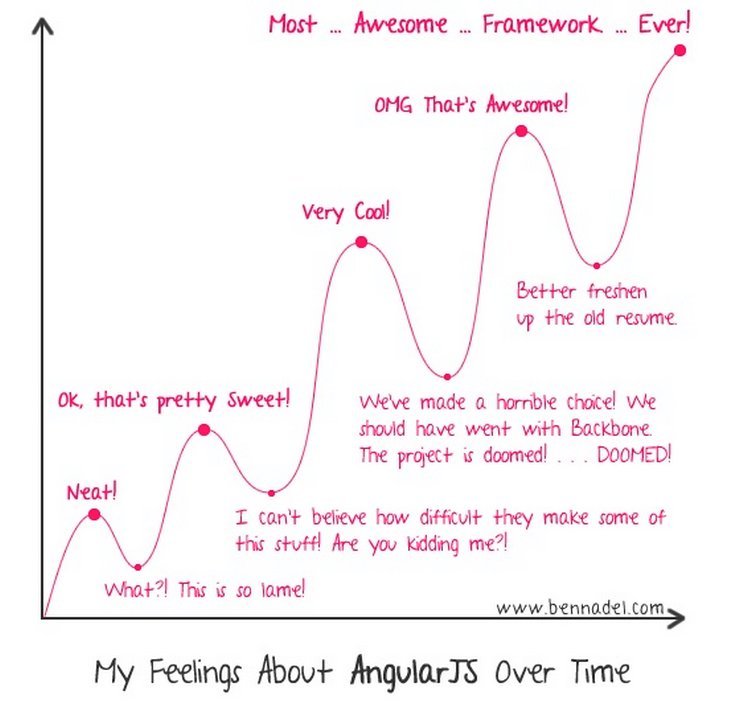
I think this describes a lot of people’s experiences around learning Angular.
Angular.js may be inappropriate.
Need Search Engine Optimization: if you need your application to be indexed by search engines, Single Page Application frameworks will make your life difficult. This is because the application is composed in the UI, so there’s not going to be anything to index if the search engine doesn’t execute the in-page JavaScript like a browser would. Google has stated that they will begin to render pages before indexing, solving the SPA problem, but there’s no commitment yet from the other search engines. In the meantime, you are left with two strategies: work around the problem by providing a set of indexable pages in addition to your SPA, or go back to a more traditional server-side MVC [4].
Need finer-grained control over DOM: Angular is going to do its best to get in between you and the DOM (that’s its intention). If you need to have more control over DOM, trying to work purely through directives may not be enough (for instance, if you’re writing something as complex as Photoshop with a lot of cross-component interactions). Honestly, I rarely see this being the case.
Encounter performance issues you can’t work around: Angular is pretty fast, but there are certain situations where dirty-state checking can be more costly than using an observer model (like Ember’s). This is quickly seen when a page has a large number of active watches on variables (keep in mind every {{variable}} is a watch!). Angular authors generally recommend staying under 2,000, mostly because experience has shown them that’s the practical limit for slower machines and older browsers. There’s also a number of tricks to optimize performance, like rendering immutable variables only once (and omitting the watch). After some tuning you might find that Angular still doesn’t provide the performance you are looking for; in that case, you may need to research another framework.*
*The new Object.observe() ECMA standard will solve a large number of these performance issues for newer browsers [5].
Node.js
Finally, we come to Node.js. It’s a great platform, but it’s not for everybody and every use case:
The JavaScript language: let’s face it, there’s a large community of developers that like statically-type languages with classic Object-Oriented Programming models. These developers tend to be spoiled with a wealth of tools like IDE’s (with syntax highlighting and code completion), debuggers, VM monitoring tools, etc. Node.js does not have this sort of support.
Concurrency model: Node.js uses a single-threaded event loop. JavaScript callbacks are essentially functions queued for execution. I don’t mind this style of concurrency, but many developers loathe it. However, there are some use cases where a thread or actor model makes more sense. In those cases, you will need to find another platform.
Ecosystem: while Node’s ecosystem is getting better each year, it’s still hard to compare to languages like Java, Python, PHP, or Ruby. There are a number of domains with substantial frameworks that have no equivalent in JavaScript: scientific computing, natural language processing, rules engines, business process management, distributed computing, security, infrastructure, virtualization, etc. Most of the time it makes more sense to write in the framework’s native language, than try to write some wrapper around it to be controlled via Node.js*.
Packaging and Deployment: in some cases, Node.js may not be appropriate simply because it’s a scripting language. This is particularly true if you are writing a product that is packaged and distributed to customers (e.g. on a CD or by download). JavaScript has no means other than minification/obfuscation for protecting your software from IP infringement or piracy. In other cases, customers may not allow a scripting language to be hosted on their servers for security reasons (we see this every once in a while with government customers).
Team considerations: most likely your team is not equipped to write server-side JavaScript. When you think about it, JavaScript was in the domain of the Web Developer for the longest time. So your experienced JavaScripters tend to be frontend guys, not backend ones. Also, server-side programming is not easy and takes a mindset quite different than frontend work. So don’t expect your Web Developers to start immediately writing quality backend code, or your server-side guys to be writing quality JavaScript.
Plenty of viable alternatives: let’s face it, there’s a lot of sexy on the backend nowaday. While Node.js may be the soup du jour of developers today, it’s completely possible that in two years it will be superseded by Golang, Elixir, Scala, Clojure or something else we’ve never even heard of. Let’s also remember that popularity in Ruby, Python, Java, and C# haven’t wained too much either. With all of these alternatives, it’s easy to find examples where applications would have been more appropriately written on another platform*.
*Keep in mind that if you ditch Node.js, you also ditch Express.js.
Conclusion
MEAN’s great, but then you grow up. My point is that you shouldn’t let the flashy new toy blind you to the fact that you are accepting serious tradeoffs. If the technology stack and programming paradigm fits your use case well, keep using it. However, if you are like the majority of developers I know, you are quickly going to discover some of the pitfalls of the architecture. In that case, I encourage you to think about the problems you are encountering, specifically, what pieces of the MEAN stack aren’t working out for you. Find compelling reasons why those pieces shouldn’t be in your system and don’t be afraid to move away if you feel it necessary.







